Abstract
The recent advent of event cameras in computer vision applications has significantly increased the performance of traditional methods, by leveraging the outstanding advantages of these novel sensors over conventional cameras. If on one hand the event-based techniques have achieved impressive results, on the other the same methods are nonetheless limited by the scarce amount of event data required for training. In this work, we propose a learning-based solution relying on Spiking Neural Networks that addresses this issue by generating event data starting from the huge amount of pre-existing video datasets recorded with conventional cameras. The Spiking Neural Networks leverage the asynchronous nature of events to generate event data in an end-to-end fashion, starting from high temporal resolution videos. We evaluate the method on different levels:
Key Idea
Research in this area has shown that computer vision techniques based on event data have achieved outstanding results, leading to a growing interest in this field. However, one the main limitations of these methods is that they require a large amount of event data for training, which is not available for mainly two reasons: first, because these sensors have been recently introduced in the market and secondly because they are rather expensive, making them not accessible to everyone.
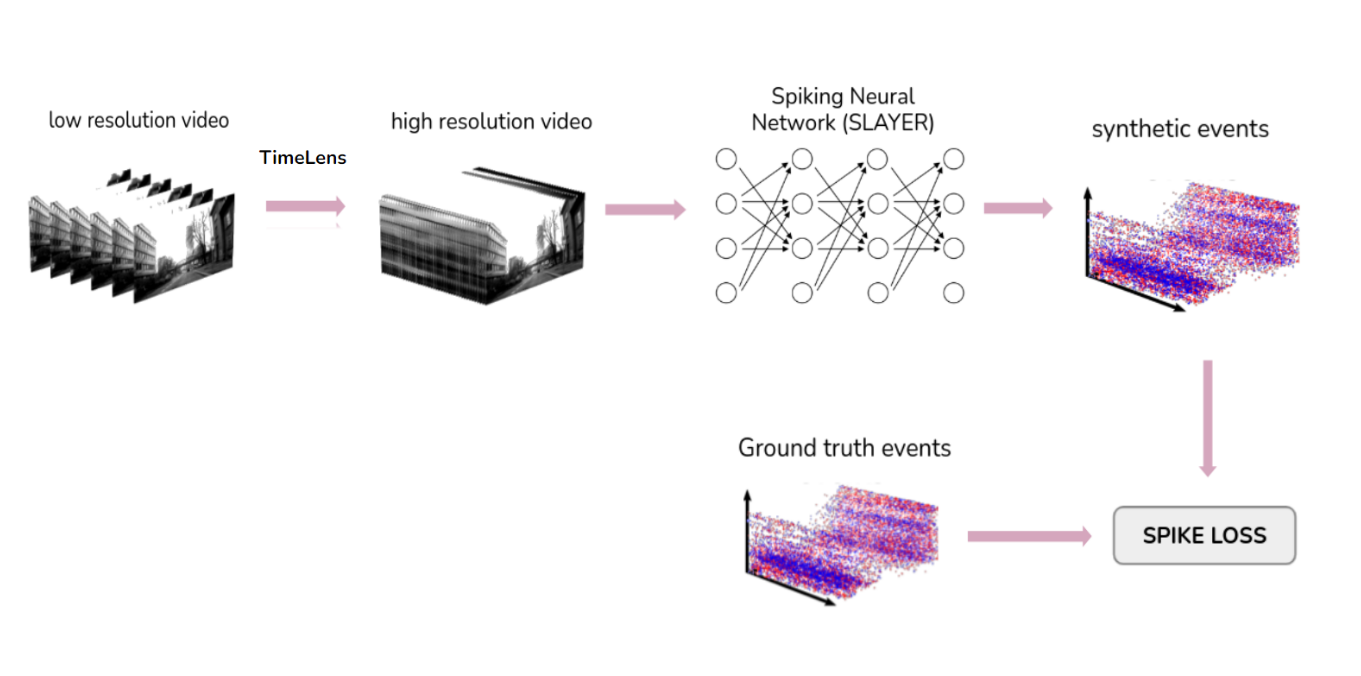
The goal of this project is to design a learning-based solution that addresses this issue by converting any existing frame-based dataset recorded with conventional cameras into synthetic event data. In this way, we can leverage the enormous amount of video datasets to automatically generate events. The general pipeline of the project can be summarized in the following steps: starting from low resolution videos, TimeLens frame interpolation technique is first deployed to generate high resolution videos which are directly fed into the event generation network. The training process of the Spiking Neural Network is supervised by a spike loss relying on ground truth events. To summarize, the main contributions are:
Method
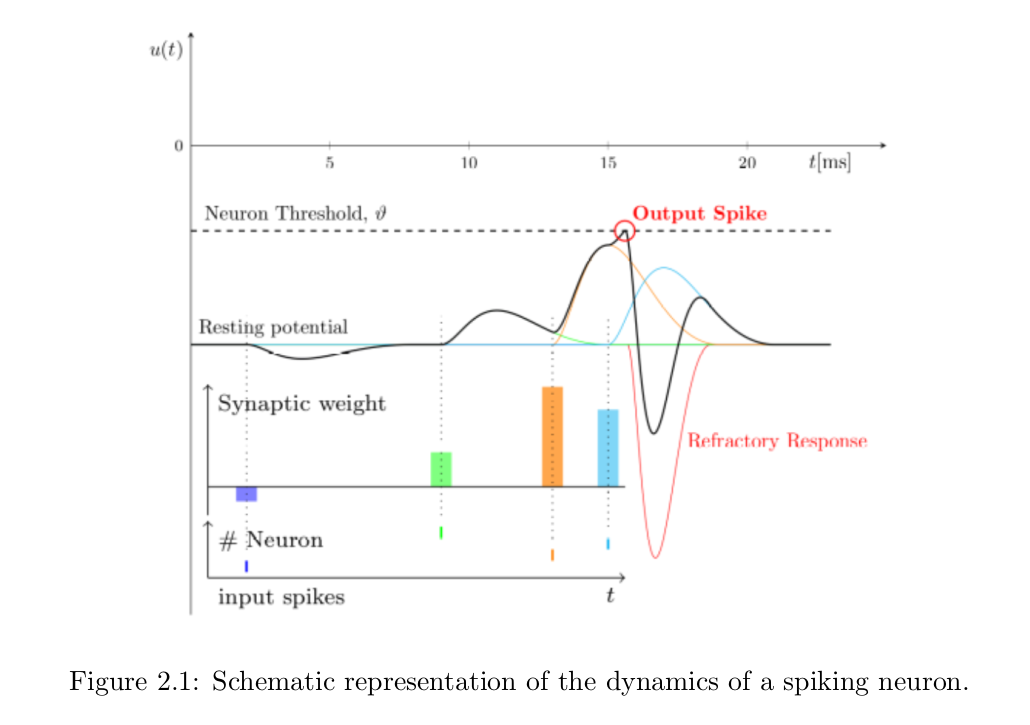
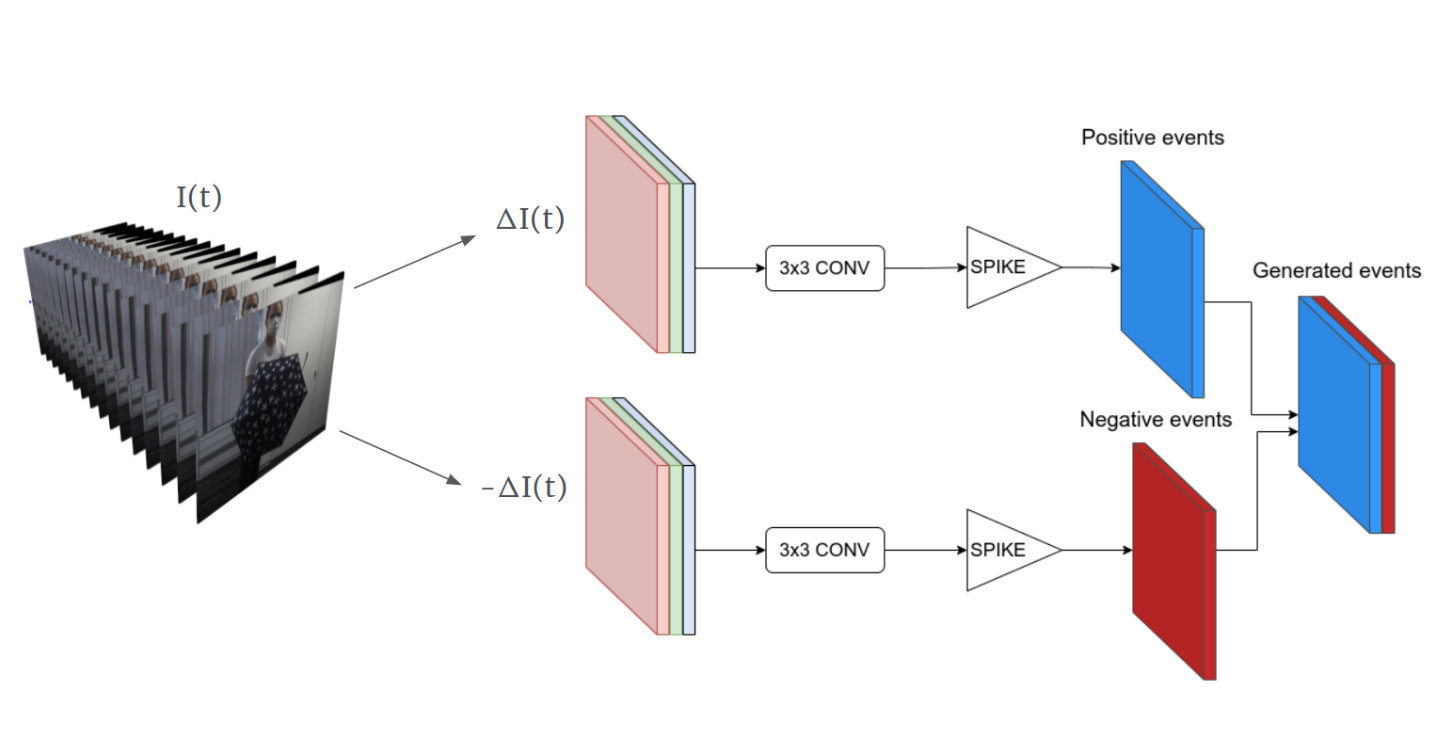
In this section we present Spike-ESIM, a novel Spiking Neural Network for event generation from video frames. The proposed network is different from traditional Spiking Neural Networks in the way that it does not take as input trains of asynchronous spikes, but rather sequences of upsampled video frames which are fed directly at the level of the membrane potential of the first layer. In this way, we skip the Post Synaptic Potential layer at the initial stage of the network, which normally convolves the input spikes of each node with the temporal ε(·) kernel to generate the potentials.
The network is a branched architecture, with each branch modeling a specific polarity of the output event tensor. Modeling the event generation process with a single network would not be feasible, since we need to account for both positive and negative changes of brightness along the frames. The way the input video frames are fed into the network is the following: starting from a sequence of T consecutive frames, we compute both the positive and negative difference of the intensities along adjacent frames, namely ∆I(t) and −∆I(t), and we feed them into the two separate branches. Each branch is composed of a 3D convolution layer followed by a spike function module, this latter being the one that actually generates events by thresholding the scaled differences of brightness according to the membrane potential hyper-parameter.
Results
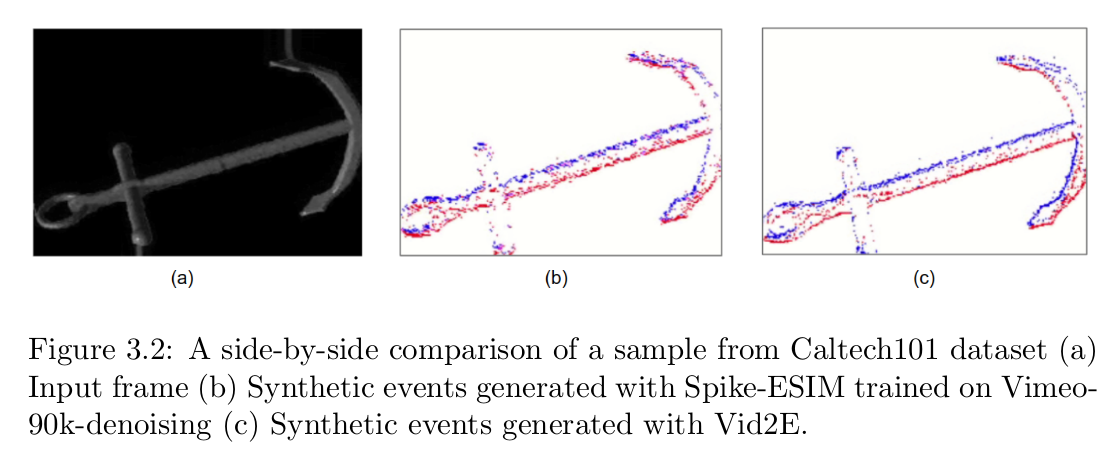
In this chapter we provide experimental results to validate the effectiveness of the proposed method. A qualitative evaluation is performed by visually comparing the generated events to the ground truth events. Visualizing the generated events reveals a strong dependency of the method on background noise present in most of the scenes of the HS-ERGB dataset. The amount of noise that is modeled in the scene is strongly dependent on the membrane threshold that we set before training, and its value is extremely important as it strikes a balance between how much noise we allow in the results and how well we want to model the real events