Key Idea
The way to achieve the final result comprises the following two building blocks:
For detailed information, please refer to poster and report.
Dataset Generation
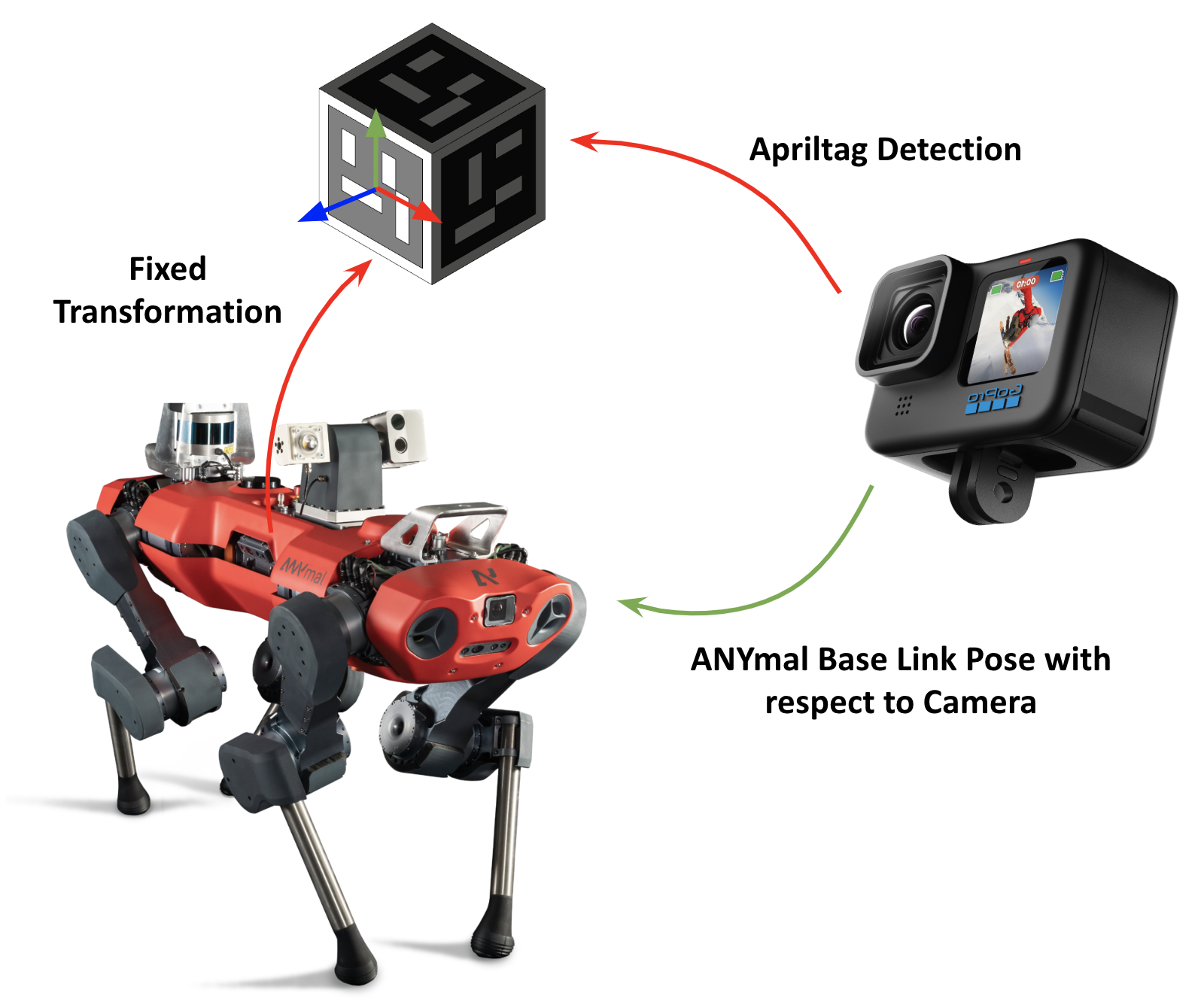
The ground truth poses of the base of ANYmal are generated by detecting AprilTags attached to a mounting fixed on top of the robot by leveraging the ROS package apriltag_ros. Then the position and quaternion is averaged between multiple faces detected in the same frame to reduce jitter.
 |  |
Pose Estimation
We adapt one of the state-of-the-art method for 6D pose estimation called EfficientPose on the generated dataset. It is based on the one-stage object detection algorithm called EfficientDet, and extends functionality to 6D pose estimation in a simple and intuitive way.
The network first extracts image features with the scalable backbone architecture EfficientNet. After that, the features are fed into a bidirectional feature pyramid network (BiFPN) to extract and fuse features at multiple scales. Finally, all features are fed into 4 sub-networks. Each block consists of a classification network, a 2D bounding box regression network and additionally a rotation and translation regression network.
What is required in order to train the network are the RGB images of ANYmal, the corresponding binary mask of the object of each frame, the 3D object model and the ground truth poses.

Results
All experiments were conducted on selected sequences of the dataset, which were manually inspected in order to filter out all the corner cases that might have affected the training procedure in a negative way. We mainly focused our experimental analysis on the training of 3 sequences, of approximately 2-3 minutes each, recorded at 30FPS in 4K. Before feeding the RGB sequences to the network, each frame is first down-sampled to a resolution 640 X 480 in order to comply with the Linemod dataset which represented the benchmark for EfficientPose.
We evaluate our approach with the commonly used ADD metric, which computes the average point distances between the 3D model point set M transformed with the ground truth and the predicted poses. In addition to the ADD metric, we also evaluate the model with the ADD accuracy score, which represents the rate of the ADD being smaller than 10% of the object diameter within each sequence.
In order to guarantee that the presence of markers in the scene would not bring meaningful information to the network while predicting the pose, we blur the cubes in the validation set and test the model on the blurred frames. Visual inspection of the results by means of 3D bounding boxes centered and oriented according to the predicted poses in each frame shows that the network generalizes well to unseen frames within the same sequence
 |  |
 |  |